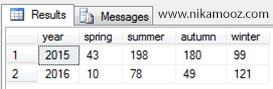
فرض کنید جدولی با نام sale و مطابق با چنین ساختاری داریم. این جدول شامل اطلاعات تعداد فروش (amount) بر اساس سال (year) و به ازای هر فصل (quarter) است.
حال می خواهیم به عنوان
مثال، اطلاعات فروش هر سال را به تفکیک هر فصل داشته باشیم. برای این کار از Aggregation Functionها
استفاده کرده و اسکریپت زیر را اجرا می کنیم:
SELECT
year,quarter,SUM(amount) AS amountSum
FROM sale
GROUP BY YEAR,quarter
ORDER BY
year
GO
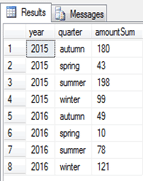
خروجی کوئری بالا، اطلاعات
فروش هر سال را به تفکیک هر فصل و در قالب یک رکورد نمایش میدهد. در ادامه اگر بخواهیم اطلاعات فروش به ازای هر سال
و بر اساس تمامی فصل¬ها صرفا در قالب یک رکورد یا یک سطر نمایش داده شود، باید چه
کار کنیم؟
با استفاده از Sub Queryها این کار امکانپذیر است!
SELECT DISTINCT
year
,(SELECT SUM(amount)FROM sale s2 WHERE s2.year=s1.year AND s2.quarter='spring') AS spring
FROM sale s1
GO
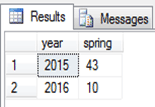
به
خروجی کوئری اجرا شده توجه کنید! این کوئری، صرفا جهت نمایش اطلاعات فروش فصل بهار
است. بنابراین برای نمایش اطلاعات سایر فصل ها، میبایست آنها را در کوئری شرکت
داد:
SELECT DISTINCT
year
,(SELECT SUM(amount)FROM sale s2 WHERE s2.year=s1.year AND s2.quarter='spring') AS spring
,(SELECT SUM(amount)FROM sale s2 WHERE s2.year=s1.year AND s2.quarter='summer') AS summer
,(SELECT SUM(amount)FROM sale s2 WHERE s2.year=s1.year AND s2.quarter='autumn') AS autumn
,(SELECT SUM(amount)FROM sale s2 WHERE s2.year=s1.year AND s2.quarter='winter') AS winter
FROM sale s1
GO
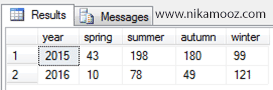
همان طور که میبینید،
توانستیم اطلاعات فروش در هر سال و به تفکیک هر فصل را در قالب یک رکورد نمایش
دهیم اما نکته قابل تامل این است که اگر تنوع بازه زمانی اطلاعات فروش بر اساس ماه
های مختلف در نظر گرفته شده بود آن گاه میبایست تمامی ماه های سال را در کوئری
شرکت میدادیم!
این موضوع در خصوص موجودیت هایی متنوع، قطعا چالش برانگیز خواهد بود
و روش بهینه ای به حساب نمیآید.
PIVOT Table چیست؟
همان طور که در شکل پایین میبینید،
خواسته ما، چرخش مقادیر داده ها از درون ستون های جدول به سمت Header گزارش است و این قابلیت به کمک PIVOT
Tableها در SQL Server
تامین میشود. به عبارت دیگر
زمانی از PIVOT Tableها
استفاده میکنیم که بخواهیم گزارش هایی از نوع Cross-Tab داشته
باشیم.

الگوی استفاده از PIVOT Tableها در
SQL به شکل زیر میباشد:
SELECT
<non-pivoted column>,
[first pivoted column] AS <column name>,
...
[last pivoted column] AS <column name>
FROM
(<SELECT query that produces the data>)
AS <alias for the
source query>
PIVOT
(
<aggregation function>(<column being aggregated>)
FOR
[<column that contains the values that will become column
headers>]
IN ( [first pivoted column], [second pivoted column],
... [last pivoted column])
) AS <alias for the pivot table>
<optional ORDER
BY clause>;
بنابراین در ابتدای کار میبایست تکلیف سه مورد زیر را
مشخص کنیم
۱- Aggregate Column: همان فیلدی است که قرار است بر روی آن عملیات Aggregation انجام
شود که در مثال فرضی ما، فیلد amount خواهد بود.
۲- PIVOT Column: فیلدی که قرار است از درون رکوردها به
سمت
Header گزارش چرخش داشته باشد که در مثال فرضی ما،
فیلد
quarter خواهد بود. این فیلد در جلو عبارت FOR قرار میگیرد.
۳- لیستی
که قرار است گزارش براساس آن تهیه شود که در مثال فرضی ما، مقادیر فیلد quarter خواهد بود که همان spring,summer,autumn,winter خواهند
بود.
اکنون
با تشخیص موارد بالا، همه چیز برای ایجاد کوئری فراهم شده است:
SELECT * FROM sale
PIVOT
(SUM (amount) FOR quarter
IN ([spring],[summer],[autumn],[winter]))pTable
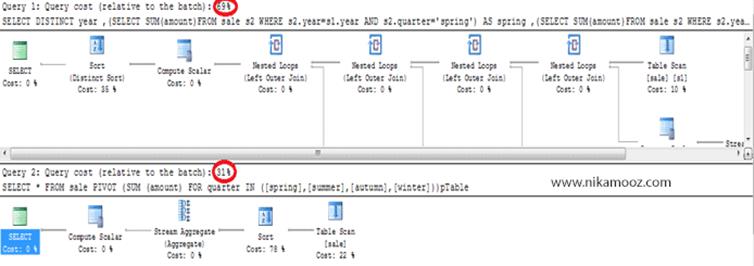
شکل زیر مقایسه میان Plan اجرایی این کوئری (استفاده از PIVOT) و
کوئری قبلی ( استفاده از Sub Query) را نشان میدهد و شما میبینید که به لحاظ کارآیی، استفاده از PIVOT Tableها به چه میزان تاثیر گذار خواهند بود. مقایسه دیاگرام Plan اجرایی این دو کوئری هم در نوع خودش جالب توجه است. از طرفی میزان
خطوط نوشته شده در هر کوئری هم جای تامل دارد!
ضمنا باید به این نکته هم
توجه داشته باشید که با استفاده از ایندکس گذاری مناسب، قطعا میتوانیم به کارآیی
بیشتر این گونه کوئری ها کمک کنیم.
در ادمه میخواهیم تغییراتی بر روی جدول sale اعمال کنیم. این
تغییرات شامل افزودن یک فیلد از نوع INT و با خصوصیت IDENTITY است:
ALTER TABLE
sale
ADD id INT IDENTITY
مجددا همان کوئری ای را که
در آن از PIVOT
استفاده شده بود، اجرا میکنیم.
خروجی کوئری، مطابق با آنچه که ما انتظارش را داشتیم، نیست!
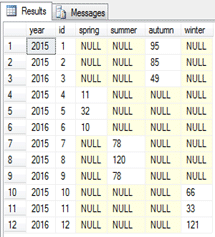
آیا میتوان چنین استنباط
کرد که قابلیت PIVOT
صرفا برای جداول سه فیلدی ایجاد شده است؟ پاسخ مثبت و چنین برداشتی،
قطعا موجب رنجش خاطر تیم توسعه دهنده Microsoft SQL Server خواهد شد!
اما مشکل کجاست و چه راهحلی وجود دارد 🤔🤔🤔
دوباره به کوئری زیر توجه
کنید. فرض میکنیم هنوز به جدول مان فیلد id را اضافه نکرده ایم.
کوئری زیر را اجرا میکنیم:
SELECT * FROM sale
PIVOT
(SUM (amount) FOR quarter
IN ([spring],[summer],[autumn],[winter]))pTable
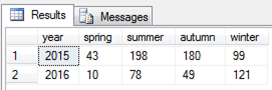
در این کوئری، SQL نتایج را بر اساس سال فروش (year) تفکیک کرده است. اما SQL از کجا تشخیص داده است که باید چنین کاری
را انجام بدهد؟ پاسخ آن است که در این حالت تمامی فیلد های یک جدول به غیر از Aggregate Column و PIVOT
Column، توسط SQL در GROUP
BY شرکت داده میشوند که در این جا شامل فیلد year میشود.
این موضوع در Plan اجرایی کوئری، به وضوح قابل مشاهده است.
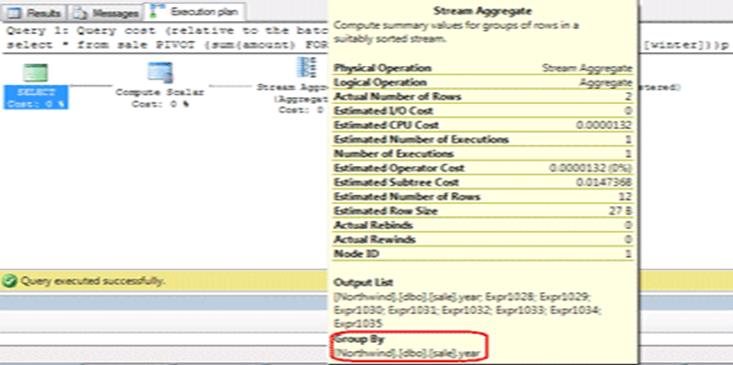
البته این قاعده در برخی از
موارد به ضرر ما تمام میشود و این همان جایی است که مثلا به جدول sale یک فیلد
id اضافه شود. آن گاه علاوه بر فیلد year، فیلد id هم در GROUP BY شرکت داده میشود و نتایج مورد انتظارمان حاصل نخواهد شد.
برای رفع چنین مشکلی میبایست به جای استفاده از SELECT ای مستقیم از جدول sale،
با استفاده از یک
Sub Query، فیلدهای
موردنظرمان را در
SELECT انتخاب کنیم.
اسکریپت زیر، نحوه انجام کار
را نشان میدهد:
SELECT * FROM
(SELECT year,quarter,amount FROM sale)s
PIVOT
(SUM(s.amount) FOR quarter
IN ([spring],[summer],[autumn],[winter])
)pTable
حال به
سراغ دیتابیس معروف
Northwind می رویم و می خواهیم بدانیم در جدول Customers به ازای کشورهای uk، spain و usa چه تعداد کارمند
داریم.
بنابراین در ابتدای کار می بایست تکلیف سه مورد زیر را مشخص کنیم:
- Aggregate Column: فیلد CustomerID
- PIVOT Column: فیلد Country
لیستی که قرار است گزارش براساس آن تهیه شود که در مثال فرضی ما،
مقادیر فیلد Country و شامل uk، spain و usa خواهد بود.
اسکریپت زیر را
اجرا می کنیم:
SELECT * FROM
(SELECT Country,CustomerID FROM
Customers)C
PIVOT
(COUNT(CustomerID) FOR Country
IN ([uk],[usa],[spain]))pTable
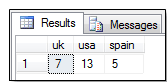
خوب، تا این جای کار همه چیز مطابق با خواسته ما بود اما آیا شما می
دانید که در جدول Customers چه کشورهایی وجود دارد؟ اگر تعداد این کشورها زیاد
باشد، آیا منطقی است که پس از شناسایی آن ها، لیست عریض و طویلی از عنوان کشورها
را در جلو IN و در ساختار PIVOT،
ردیف کنیم؟ آیا این امکان وجود ندارد که در آینده عناوین کشورهای جدیدی به جدول
مان اضافه شوند؟ و …
پاسخ مناسب به حل مشکلات
مطرح شده، استفاده از Dynamic T-SQL خواهد بود.
Dynamic T-SQL در واقع اسکریپت هایی است که به صورت
Dynamic ایجاد
می کنیم و در همان لحظه، آن ها را اجرا می کنیم. با استفاده از Dynamic T-SQL می توان شرایطی پویا و متنوع در زمان اجرای یک کوئری ایجاد کرد.
در اسکریپت زیر، متغیرهای
مورد نیاز را تعریف و مقداردهی کرده و سپس با الحاق مناسبی با عبارات T-SQL، از طریق EXEC آن ها را اجرا می کنیم.
اکنون برای آن که بتوانیم یک
Dynamic PIVOT داشته
باشیم، دقیقا از این تکنیک استفاده می کنیم.
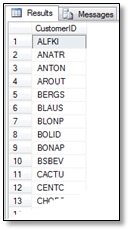
فرض می کنیم که می خواهیم
بدانیم از هر کشور چه تعداد مشتری داریم. پس می بایست لیست کشورهای موجود را از
جدول Customers استخراج کنیم.
DECLARE @country VARCHAR(MAX)
SET @country=''
SELECT
@country=@country+Country+',' FROM Customers
GROUP BY Country
SET
@country=LEFT(@country,LEN(@country)-1)
ابتدا
متغیرcountry@ را تعریف می کنیم. در خط دوم اسکریپت بالا، ابتدا
مقدار country@ را برابر
Blank قرار می دهیم.
توجه داشته باشید که اگر این کار را انجام ندهید با مشکل روبرو خواهید شد زیرا در
ابتدا، مقدار country@ در هنگام تعریف، برابر با
NULL خواهد بود و
همواره جمع یک رشته با NULL برابر با
NULL خواهد شد!
در عبارت SELECT، تمامی کشورها را از طریق
جدول Customers در متغیرcountry@ به همراه جداکننده ویرگول، ذخیره می کنیم. توجه داشته باشید که
استفاده از GROUP BY به منظور جلوگیری از درج تکراری عناوین کشورها است.
در خط آخر هم با توجه به
این که در انتهای رشته ی country@ یک علامت ویرگول اضافی
داریم، آن را حذف می کنیم.
لیست تمامی کشورها در
متغیر country@ ذخیره شده و می بایست آن را به عنوان لیست مورد
جستجو در جلو عبارت IN در ساختار PIVOT قرار دهیم.
EXEC('SELECT * FROM
(SELECT Country,customerID FROM
Customers)C
PIVOT
(count(customerID) FOR Country
IN ('+@country+'))pTable')

و اما حالا شما به عنوان
تمرین، تلاش کنید کوئری ای بنویسید که خروجی زیر را نمایش دهد. این خروجی قرار است
گزارشی باشد که عناوین همه customerIDها در Header قرار گرفته و متناسب با هر کدام، CompanyNameشان نمایش داده شود.
